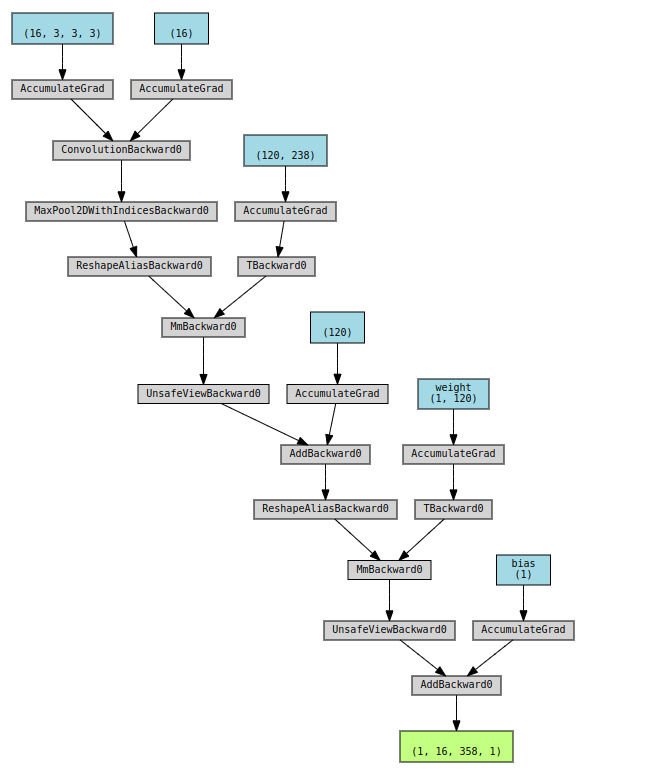
computation graph
- AccumulateGrad: 把反传下来的梯度累积加到param.grad:
param.grad += incoming_gradient conv1.weight的(16, 3, 3, 3)中- 16: output channels
- 3: input channels
- 3, 3 : kernel size
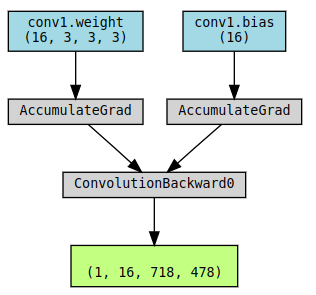
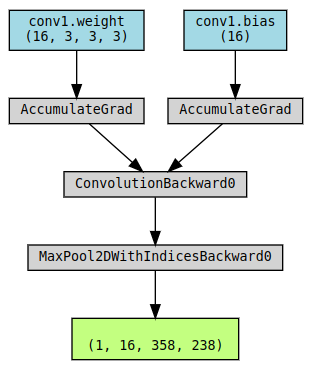
- MaxPool2DWithIndicesBackward: indice是当使用maxpool的时候因为取的是局部窗口的最大值,所以记录下最大值的位置。MaxPool没有参数(weight/bias),只是一个操作,所以也不需要AccumulateGrad
added full connected layer:
- TBackward: Transpose, 自动把weight做transpose
.t() - AddmmBackward: add + matrix multiplication. -
addmm(input, weight.T, bias)≈Linear(input, weight, bias) - ViewBackward :
.view()或.reshape(),
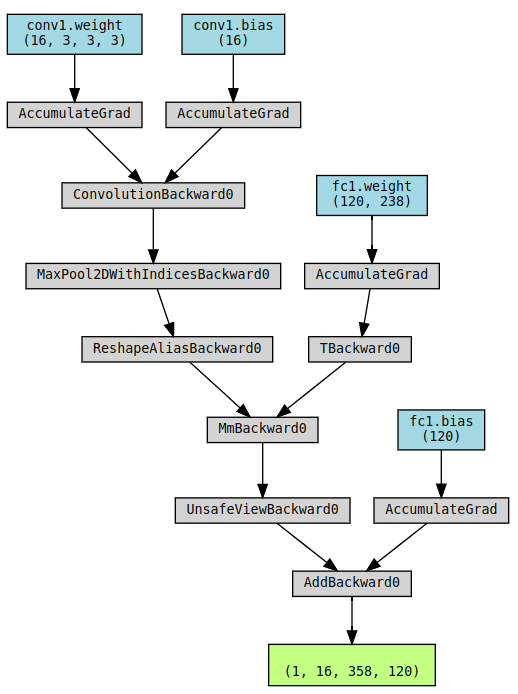
这些node上带backward的都是在做反向传播的时候会用到的