Stable Diffusion
Feb 19
Conda env
create conda env (make sure things are installed under conda env, not system one, check conda note) —> make sure kernel work (not sure if i really using kernel, will revisit here) —> just using Examples on the website
explore general diffusers
DiffusionPipeline is the easiest way to use pretrained diffusion system for inference
very basic:
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("stable-diffusion-v1-5/stable-diffusion-v1-5", use_safetensors=True)then in pipeline, it showing
StableDiffusionPipeline {"_class_name": "StableDiffusionPipeline","_diffusers_version": "0.32.2","_name_or_path": "stable-diffusion-v1-5/stable-diffusion-v1-5",
"feature_extractor": [ "transformers", "CLIPImageProcessor" ],
"image_encoder": [ null, null ],"requires_safety_checker": true,
"safety_checker": [ "stable_diffusion", "StableDiffusionSafetyChecker" ],"scheduler": [ "diffusers", "PNDMScheduler" ],"text_encoder": [ "transformers", "CLIPTextModel" ],
...
"vae": [ "diffusers", "AutoencoderKL" ] }- feature extractor:
CLIPImageProcessorfor processing input image - text encoder:
CLIPTextModel - VAE:
AutoencoderKL
Move the generator to GPU or CPU
pipeline.to("cuda")pipeline.to("cpu")verify that it does moved to gpu
pipeline.unet.device pipeline.vae.device
check if cuda available
import torchprint(f"CUDA available: {torch.cuda.is_available()}")print(f"Current device: {torch.cuda.current_device()}")print(f"Device name: {torch.cuda.get_device_name()}")check GPU usage
import torchprint(f"GPU memory allocated: {torch.cuda.memory_allocated() / 1e9:.2f} GB")Feb 20
models
you can mix models to create another diffusion system
- models are initiated with the from_pretrained() method, which also locally caches the model weights so it is faster the next time you load the model
from diffusers import UNet2DModel
repo_id = "google/ddpm-cat-256"model = UNet2DModel.from_pretrained(repo_id, use_safetensors = True).from_pretrained: common method, load pre-trained models- not all model have
from_pretrained - safe tensor is newer safer format for storing ML models, traditional formats like .bin and .pkl can potentially contain malicious code
- faster to load than traditional formats
model.config
a frozen dictionary, which means those parameters can’t be changed after the model is created
- batch axis: model can receive multiple random noises
- channel axis: corresponding to the number of input channels
- sample_size axis : height and width of the image
generate a noise array
import torchtorch.manual_seed(0)noisy_sample = torch.randn(1, model.config.in_channels, model.config.sample_size, model.config.sample_size)noisy_sample.shapeTo generate actual examples, you will need a scheduler to guide the denoising process
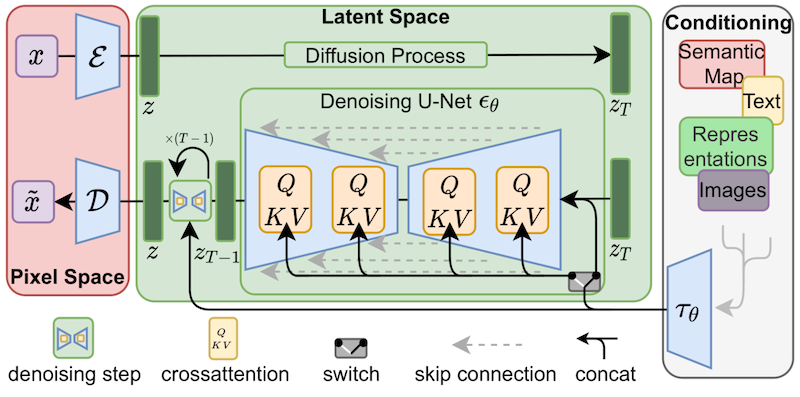
Scheduler/Noise scheduler
Schedulers are algorithms that are used alongside the UNet component of the stable diffusion pipeline. They controls how noise is added and removed during the diffusion process.
- PNDMScheduler (default)
- EulerDiscreteScheduler
During training : It defines how much noise to add at each step
During inference: It guides how to gradually remove noise to create the image
Different type of Schedulers:
- DDPM(faster)
- DDIM(faster, deterministic)
- DPM-solver
- Euler ancestral…
VAE is used for making the diffusion process more efficient
pseudo code show the who process
# Simplified examplescheduler = DDPMScheduler()vae = AutoencoderKL.from_pretrained("stabilityai/sd-vae-ft-mse")
# During inference:latents = noise # Start with random noisefor t in scheduler.timesteps: # 1. Predict noise residual noise_pred = unet(latents, t) # 2. Scheduler guides noise removal latents = scheduler.step(noise_pred, t, latents)
# Finally, decode to imageimage = vae.decode(latents)noise residual
” I think THIS is the noise that was added”
It’s predicting what the noise looks like
# Simplified example of how it works:original_image = clean_imagenoisy_image = original_image + random_noise
# Model tries to predict the random_noisepredicted_noise = model(noisy_image) # This is the noise residual
# During denoising:denoised_image = noisy_image - predicted_noiseSet up large git file
!git lfs install!git clone https://huggingface.co/stable-diffusion-v1-5/stable-diffusion-v1-5in terminal :
sudo dnf install epel-releasesudo dnf install git-lfswith torch.no_grad(): noisy_residual = model(sample=noisy_sample, timestep=2).samplewith torch.no_grad(): temporary disable gradient calculation. It tells pytorch dont track operations for gradient computations
- use less memory because no need to store gradient information
- make inference faster, so commonly used during inference/testing when you don’t need to update weights
model(sample=noisy_sample, timestep=2).sample :
calling the UNet model to predict the noise residual
- noisy_sample: the input image with noise added to it
- timestep = 2: denoising step
- .sample : get actual prediction output
Overal:
- taking a noisy image
- asking the model what noise was added to this image at timestep 2
- the model returns its prediction of what noise was added
- this prediction can be then used to help denoise the image
(like spot the difference between the clean image and the noisy one)